TrOCR Fine-tuning for Arabic
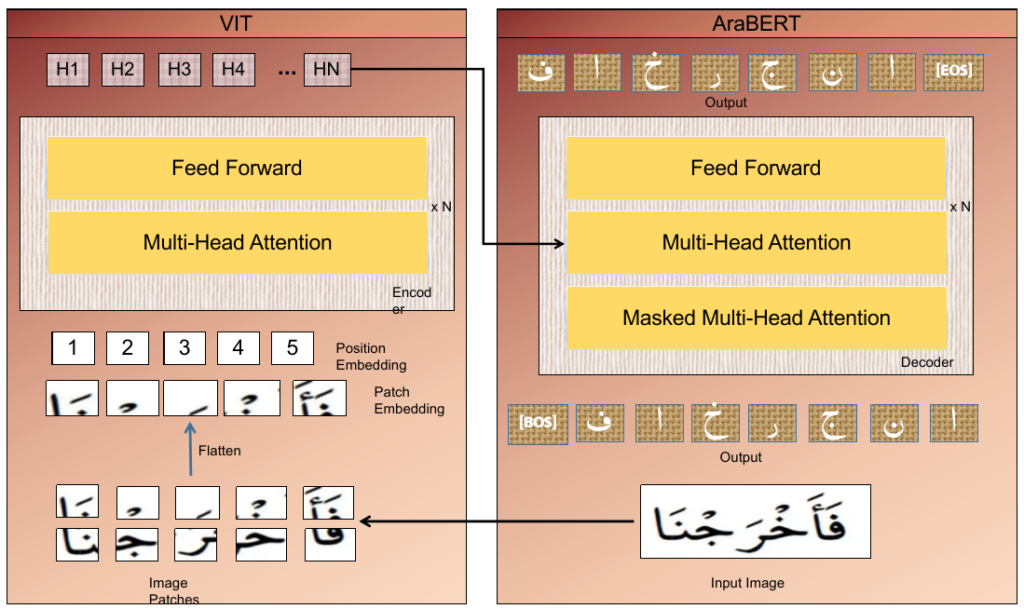
This project propels deep learning technology into the intricate universe of Arabic diacritics text recognition, an extremely challenging task in the field of Natural Language Processing (NLP). We are utilizing the TrOCR model, employing a Vision Transformer as an encoder and the AraBERT model as a decoder. This combination forms a robust architecture adept in processing images and understanding Arabic texts.

Completion Date: May 2023 | Tools: TrOCR, HuggingFace, ViT, AraBERT , Flask
Introduction
The complexity of Arabic text recognition, especially with diacritics, represents a major challenge in the field of Natural Language Processing (NLP). The TrOCR Fine-tuning for Arabic project takes on this formidable task by employing advanced deep learning models to recognize Arabic text with diacritics. This case study explores the challenges, the innovative solutions, and the wide-reaching impact of this endeavor.
The Challenge
- Arabic Diacritics Text Recognition: Arabic text with diacritics is intricate and poses specific challenges for optical character recognition (OCR). Recognizing various styles and formats required precise calibration.
- Integration of Vision and Language Models: Merging the Vision Transformer as an encoder with AraBERT as a decoder in a cohesive architecture was a complex process.
- Utilizing a Specific Dataset: The Quranc Dataset for OCR, a rich corpus of Arabic text from the Holy Quran, needed to be efficiently processed to train the model.
- Wide Applications and Accessibility: The project aimed for widespread applications, including digital Quranic studies and assisting visually impaired individuals. Ensuring that the model could cater to these varied applications was a significant challenge.
What We Did to Solve the Challenge
- Employing TrOCR Model: The team utilized the TrOCR model, fine-tuning it to recognize Arabic text with diacritics. This involved the integration of a Vision Transformer as an encoder and AraBERT as a decoder, forming a robust architecture.
- Utilizing the Quranc Dataset: The Quranc Dataset for OCR was leveraged, providing an authentic and diverse range of Arabic texts with diacritics. This dataset was key in achieving the fine-tuning necessary for the model’s goals.
- Iterative Training and Refinement: An iterative training process, alongside continuous testing and refinement, ensured that the model became adept at recognizing various styles and formats of Arabic text.
- Optimization for Varied Applications: The model was optimized for multiple applications, from academic studies to accessibility solutions. This required thoughtful design and alignment with the end-user needs.
Impact and Conclusion
The TrOCR Fine-tuning for Arabic project represents a major advancement in the field of Arabic text recognition. By skillfully combining vision and language models and fine-tuning them on a specific dataset, the project has achieved remarkable success in recognizing Arabic diacritics text.
The potential applications are broad and significant, including aid in digital Quranic studies, improvements to automated translation systems, and support for visually impaired individuals in accessing Arabic literature.
This project not only breaks down language barriers but also fosters cultural and scholarly connections, making Arabic literature more accessible and understandable. It stands as a model of innovation, precision, and inclusiveness, highlighting the transformative power of AI in bridging linguistic and cultural gaps.
The TrOCR Fine-tuning for Arabic project is indeed a beacon of technological advancement, reflecting the boundless possibilities of deep learning in addressing complex language tasks. It’s a vital step in the ongoing journey of leveraging AI to enrich human understanding and connection across different languages and cultures.