
Introduction
The Institute of Technological Innovations from the UAE has unveiled Falcon 180B, the largest open language model, displacing Llama 2 from the top spot in the rankings of pre-trained open-access language models by HuggingFace. The model was trained on 3.5 trillion tokens using the RefinedWeb dataset. Falcon boasts 180 billion parameters, which is 2.6 times more than the previous leader, Llama 70B, requiring 8 Nvidia A100 GPUs and 400GB of space for inference. You can test the model on HuggingFace, and the model’s code is also available there.
What is Falcon-180B?
Falcon 180B is a model released by TII that follows previous releases in the Falcon family.
Architecture-wise, Falcon 180B is a scaled-up version of Falcon 40B and builds on its innovations such as multiquery attention for improved scalability. It was trained on 3.5 trillion tokens on up to 4096 GPUs simultaneously, using Amazon SageMaker for a total of ~7,000,000 GPU hours. This means Falcon 180B is 2.5 times larger than Llama 2 and was trained with 4x more compute.
Hardware requirements
We ran several tests on the hardware needed to run the model for different use cases. Those are not the minimum numbers, but the minimum numbers for the configurations we had access to.
| Model | Type | Kind | Memory | Example |
| Falcon 180B | Training | Full fine-tuning | 5120GB | 8x 8x A100 80GB |
| Falcon 180B | Training | LoRA with ZeRO-3 | 1280GB | 2x 8x A100 80GB |
| Falcon 180B | Training | QLoRA | 160GB | 2x A100 80GB |
| Falcon 180B | Inference | BF16/FP16 | 640GB | 8x A100 80GB |
| Falcon 180B | Inference | GPTQ/int4 | 320GB | 8x A100 40GB |
Model Architecture
Falcon 180B, a fine-tuned version of Falcon 40B, utilizes a multi-query attention mechanism for enhanced scalability. The conventional multi-head attention scheme features one query, key, and value for each head, whereas the multi-query approach uses a single key and value for all “heads.”
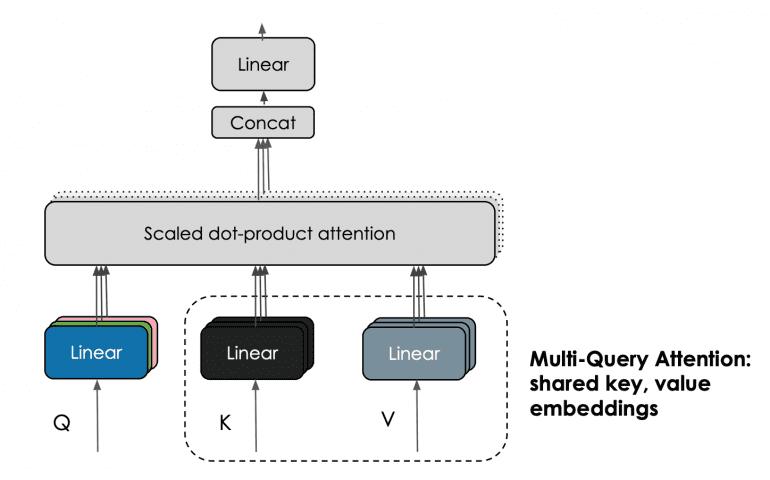
The model was trained on 4096 GPUs, which took approximately 7,000,000 GPU hours on Amazon SageMaker. Compared to Llama 2, training Falcon 180B required four times more computational power.





