As we navigate the landscape of 2026, the initial era of generative AI experimentation has yielded to a period of industrial-grade Enterprise LLM Implementation. For technical founders and CTOs, the fundamental challenge is no longer just selecting a foundational model, but architecting a system that safely bridges the 'Enterprise Data Gap' - the distance between a model's public training weights and your organization's proprietary intelligence.
In our internal analysis of scaling enterprise AI systems, we found that optimizing data retrieval pipelines can reduce hallucination rates by up to 85% compared to baseline models. The decision between Retrieval-Augmented Generation (RAG), Fine-Tuning, and Prompt Engineering is no longer a theoretical debate; it is a critical infrastructure choice that dictates your compute costs, latency, and system scalability.
This guide provides a practitioner's framework for architecting Large Language Models (LLMs) for maximum ROI, security, and production-grade accuracy.
The Engineering Reality: Moving Beyond Base Models
Base models are essentially 'polymaths with amnesia.' They possess vast general knowledge and reasoning capabilities but lack access to your internal databases, real-time analytics, and secure corporate data.
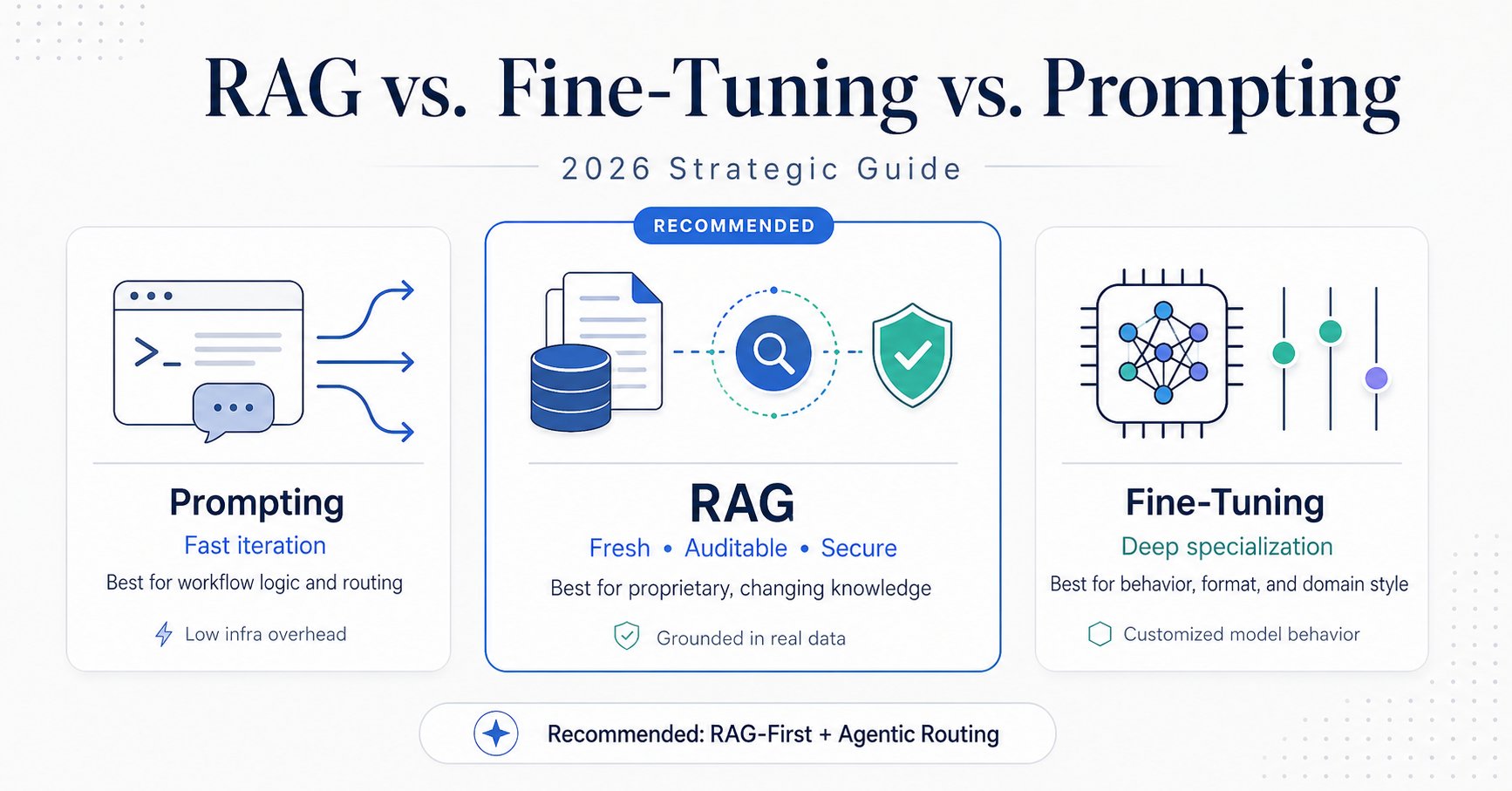
To transform these models into production-ready assets, engineering teams must leverage one of three primary optimization levers. A common mistake is assuming that adjusting model weights (Fine-Tuning) is the default solution for poor performance. In reality, the most resilient architectures today are hybrid systems that utilize multi-agent workflows for routing, RAG for factual grounding, and fine-tuning exclusively for deep stylistic or logical specialization.
Option A: Advanced Prompting & Multi-Agent Routing (The Agility Play)
Architectural Overview
Prompt engineering has evolved far beyond basic text instructions. In 2026, it involves programmatic prompt construction and multi-agent orchestration frameworks like LangGraph. Instead of relying on a single zero-shot prompt, we design stateful, multi-actor systems where agents dynamically construct prompts based on the user's intent before routing the query to the appropriate LLM.
The Engineering Trade-offs
- Pros: Near-zero infrastructure overhead; instantaneous iteration; highly effective when combined with stateful agentic workflows.
- Cons: Strictly bounded by the model's context window limits; highly susceptible to prompt injection attacks; prone to 'mode collapse' when instructions become too complex.
Production Use Case
Best utilized as the routing layer of an AI application. For example, using a lightweight model to classify an incoming query and dynamically inject the correct system prompt before passing it to a heavier model for execution.
Option B: Retrieval-Augmented Generation (The Contextual Powerhouse)
Architectural Overview
RAG is the industry standard for bridging LLMs with proprietary data. Instead of baking knowledge into the model's weights, RAG relies on a high-speed semantic search pipeline.
When dealing with large-scale vectorization projects - often scaling up to 300-400GB of enterprise data, a naive RAG approach fails. Production RAG requires a robust pipeline:
- Ingestion & Chunking: Parsing raw data and applying semantic chunking strategies to preserve context.
- Embedding: Passing chunks through an embedding model to create dense vector representations.
- Vector Store: Storing these embeddings in a high-performance vector database.
- Retrieval & Generation: Intercepting a user query, converting it to a vector, retrieving the Top-K nearest neighbors, and injecting that context into the LLM's prompt via a scalable backend (typically built on FastAPI).
The Engineering Trade-offs
- Pros: Absolute data freshness; highly auditable (you can trace exact source documents); inherently secure through document-level access controls.
- Cons: Introduces latency during the retrieval step; requires maintaining separate infrastructure (Vector DBs, embedding pipelines).
Production Use Case
RAG is the definitive architecture for systems requiring factual accuracy and real-time updates, such as medical clinical assistants parsing dynamic guidelines or financial chatbots querying live internal knowledge bases.
Option C: Fine-Tuning (The Deep Expertise Specialization)
Architectural Overview
Fine-tuning permanently alters the internal parameters (weights) of a pre-trained model. Rather than providing context at runtime, you are retraining the model on a highly curated, domain-specific dataset. Modern Parameter-Efficient Fine-Tuning (PEFT) methods, such as LoRA and QLoRA, allow teams to freeze the base model and only update a small subset of weights, drastically reducing compute requirements.
The Engineering Trade-offs
- Pros: Unmatched performance in niche logical tasks; highly effective at forcing models to output specific structural formats (like proprietary code or strict JSON); reduces runtime latency compared to heavy RAG prompts.
- Cons: High risk of 'Knowledge Obsolescence' (data is frozen at training time); expensive data curation process; difficult to enforce user-level data security.
Production Use Case
Reserved for tasks where reasoning style, format, and domain jargon outweigh the need for real-time data. Ideal for proprietary code generation, strict regulatory compliance parsing, or altering the inherent 'voice' of an open-source model.
RAG vs Fine-Tuning vs Prompting: The Infrastructure Matrix
When architecting a solution, evaluate these critical dimensions:
- Data Freshness: RAG provides real-time access. Fine-tuning is static.
- Hallucination Mitigation: RAG grounds outputs in provided facts. Fine-tuning can actually increase confident hallucinations if the training data is flawed.
- Security & Access Control: RAG allows for Role-Based Access Control (RBAC) at the database level. Fine-tuning bakes data into the weights, making it accessible to anyone who queries the model.
- Infrastructure Load: RAG shifts the load to memory and database I/O. Fine-tuning shifts the load to heavy GPU compute.
Strategic Recommendation for AI Architecture in 2026
For engineering leaders, the optimal architecture is a RAG-First Strategy wrapped in Agentic Routing.
By building a robust RAG architecture, you create a system that is grounded, auditable, and secure. Utilize frameworks like LangGraph to orchestrate prompt-based agents that handle logic and routing, and reserve fine-tuning strictly as a surgical tool for edge cases where the LLM struggles to grasp domain-specific formatting.
Choosing the right path for LLM optimization is the difference between an AI product that scales efficiently and a fragile system that becomes a technical liability.
At EnDevSols, we specialize in architecting production-grade multi-agent workflows and high-capacity RAG pipelines for enterprise clients. If you are a CTO or technical founder looking to transition from AI prototypes to scalable infrastructure, explore our Generative AI Development Services to see how we build resilient AI systems.