RetNet vs Transformer: The Battle for NLP Supremacy

In the realm of natural language processing (NLP), the Transformer architecture has emerged as the dominant paradigm. This groundbreaking architecture has revolutionized the field. This will result in achieving remarkable performance across a wide range of tasks, including machine translation, question answering, and text summarization. However, despite its remarkable success, the Transformer faces certain limitations, particularly in terms of efficiency and scalability. RetNet, a novel neural network architecture, has emerged as a potential challenger to the Transformer’s dominance. Introduced by Microsoft researchers, RetNet aims to address the limitations of the Transformer while maintaining its impressive performance.
Transformer Architecture and Features
The Transformer architecture, introduced in 2017, is based on the concept of self-attention, which allows the model to capture long-range dependencies within text without relying on recurrent connections. This approach enables the Transformer to effectively process and understand complex relationships between words in a sentence.
Key features of the Transformer architecture include:
- Encoder-Decoder Structure: The Transformer employs an encoder-decoder structure, where the encoder processes the input sequence of words, and the decoder generates the output sequence.
- Self-Attention Mechanism: The Transformer utilizes self-attention to compute pairwise relationships between words within a sequence, allowing for context-aware processing.
- Positional Encoding: To capture the order of words in a sequence, the Transformer employs positional encoding, which is added to the input embeddings
RetNet Architecture and Features
RetNet is a novel neural network architecture that has been shown to outperform the Transformer on a number of natural language processing (NLP) tasks. RetNet is based on the idea of retentive attention, which is a new type of attention mechanism that allows the network to better capture long-range dependencies in text.
RetNet Architecture
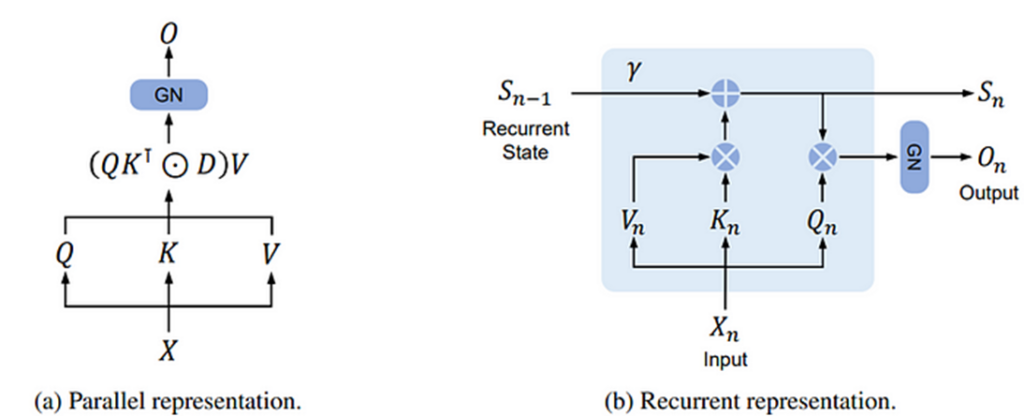
It consists of an encoder-decoder structure, similar to the Transformer. The encoder takes an input sequence of words and produces a representation of the sequence. The decoder then takes this representation and produces an output sequence of words.
The encoder and decoder both consist of a stack of RetNet blocks. Each block consists of two main components:
- Retentive Attention: This is the core of the RetNet architecture. It allows the network to maintain a consistent representation of the input sequence throughout the network.
- Feedforward Network: This is a standard feedforward network that is used to process the output of the retentive attention layer.
RetNet Features
In addition to retentive attention, it also includes a number of other features that make it more efficient and scalable than the Transformer. These features include:
- Group Norm: This is a type of normalization that is more efficient than the LayerNorm normalization that is used in the Transformer.
- Parallelizable Training: This means that RetNet can be trained on multiple GPUs or CPUs in parallel, which can significantly reduce training time.
RetNet’s advantages over Transformer:
Efficiency:
It’s retentive attention mechanism allows it to maintain a consistent representation of the input sequence throughout the network, leading to reduced memory consumption and faster inference compared to the Transformer.
Scalability:
It’s parallelizable training enables efficient training on large datasets, paving the way for the development of large-scale language models.
Performance:
It exhibits comparable or even better performance than the Transformer on various NLP tasks, demonstrating its ability to maintain high performance while addressing the Transformer’s limitations.
In summary, RetNet offers significant advantages over Transformer in terms of efficiency, scalability, and performance, making it a promising contender in the field of NLP.
Conclusion:
RetNet emerges as a promising contender in the realm of NLP, addressing the limitations of the Transformer while maintaining its impressive performance. Its retentive attention mechanism, GroupNorm, and parallelizable training capabilities offer significant advantages in terms of efficiency, scalability, and performance. As RetNet continues to develop, it has the potential to revolutionize the landscape of natural language processing.